前面几次的分享,我从一个数据驱动的实现展开去,先后讨论了什么是数据驱动,如何实现数据驱动,数据驱动在自动化框架里如何应用。
测试框架–教你用Python实现数据驱动1
测试框架–教你用Python实现数据驱动2
测试框架–数据驱动动态增加测试用例
测试框架实践–动态挑选待运行测试用例
因为这些是一个测试框架必不可少的部分,看看前面4次的分享,虽然可以成功的运行,但我们采用了顺序运行的方式,跟实际使用相差很远,现实中我们一般实现“并发”运行我们的测试用例。
说起并发,Python 有多线程(Multiple Threading)和多进程(Multiple Process)之分, 由于GIL即Global Interpreter Lock(全局解释器锁)的存在,python多线程并不能实现真正的并发(无论你的CPU是否多核),相反,多进程因为有独占的内存空间可以真正的实现并发。但在我们的自动化测试框架里,我们还是希望利用线程的公用内存空间特性,特别是同一个测试类我们希望有统一的setup, teardown特性。而这个多进程就不太适用,加上我们测试用例也不是CPU计算密集型,多线程方案的“并发”看起来是最佳选择。
但是是不是就一定要用threading.Thread呢?
我们先看看”传统“的多线程并发。 一个通用的多线程模板是这样的:
把我们前面实现的顺序运行改成并发, 只需要改成如下就可以实现多线程:
可以看到,你自己要做很多事情来保证多线程的正常运行,你要维护queue,要注意资源锁,你要使用join来等待子线程都完成。 多线程难道都这么麻烦吗?
“人生苦短,我用python”不知道你们听过没 :)
multiprocessing.dummy 来助你一臂之力!
dummy是multiprocessing的一个克隆体,唯一的区别在于,dummy使用线程而multiprocessing使用进程。
看下图,左边是传统的threading.Thread的多线程用法, 右边是multipleprocess.dummy的用法。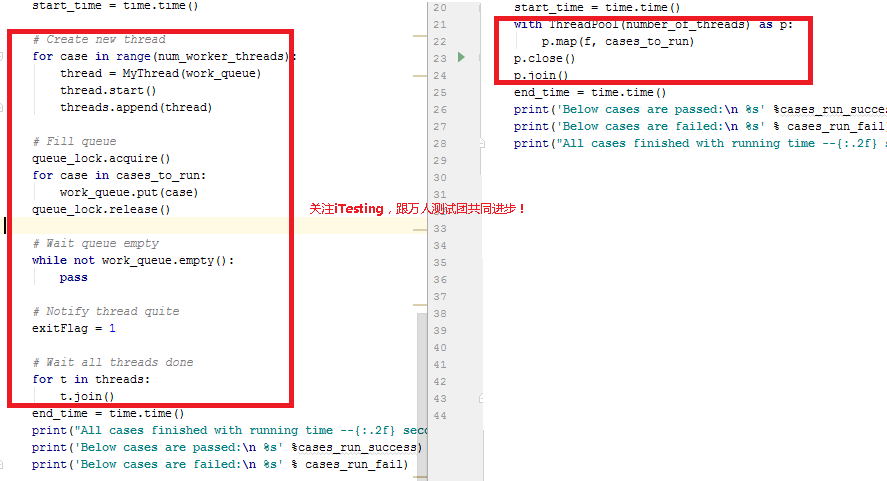
除开定义Thread类外,threading.Thread还用了这么多篇幅才能令多线程工作,但multiprocessing.dummy只用一个Pool就全搞定了。
好了,今天我们讲到这里,并发也实现了,动态挑选也实现了,一个测试框架就搭起来来, 后面就是增强了, 下一期来实现test fixture, 敬请期待!


