之前分享过很多优秀的测试框架,总觉得意犹未尽,干脆自己撸起袖子写一个。 添加微信公众号iTesting 查看原文。
在自动化测试的过程中,测试框架是我们绕不过去的一个工具,无论你是不需要写代码直接改动数据生成脚本,还是你需要检查测试结果甚至持续集成,测试框架都在发挥它的作用。
不同编程语言的实现出来的框架也不尽相同,但是思想总是相通的,比如尽量使框架使用者只关注自己的业务,框架帮助处理错误截图,保存错误log,出错重试甚至跟jenkins持续集成等。
可以说,一个还算合格的测试框架,可以大大提升测试效率;一个优秀的测试框架,说它能把测试人员从繁缛复杂的跟业务无关但又不得不做的工作中解脱出来也不为过。既然框架的作用这么明显,那么有哪些优秀的测试框架可以给我们用呢?
大家都知道, java里有TestNG, python里有unittest,pytest等优秀的“官方”框架, 我对python比较熟悉,之前也介绍过很多这方面的文章,相信大家也多少看过一两篇。
可以说,能把这些经过百万人检验的“官方”测试框架工具用好用顺,拿下本职工作根本不在话下,更不用说你还能用好围绕着这些工具的生态库了,那简直是如入无人之地。
那么,为什么还要自己写一个框架呢?
相信常做自动化的都有自己的感悟, 比如自己业务没那么复杂,官方框架显得太重了;比如官方框架依赖很多的第三方库,每个要单独安装,更新,而且每个都有自己的用法,学习成本高;
再比如说,鞋子合脚不合脚,有的人要穿7年才能知道(对,那谁)。
痛点:
对于常用python写自动化的来说,unittest本身很优秀,但是不支持并发,而且测试报告支持的也不好,也不支持数据驱动。
pytest那里都好,就是吃了酒香不怕巷子深的亏,那个docouments真要心非常静才能读下去, 另外什么功能都需要额外安装一个库,你想并发?好,装一个pytest-parallel,你想报告html展示?好,装个pytest-html, 你想要错误的测试用例自动重跑一遍?好,装个pytest-rerunfailures。 强大是强大,感觉有点过于繁琐了。
解决方案:
基于上述痛点,大部分同学选择在原有开源框架上二次开发,比如unittest集合多线程threading.Thread实现并发,加入HTMLTestRunner实现报告展示,引入ddt实现数据驱动,然后美其名曰,我写了个框架,我每次听到都是先很崇拜,然后晚上暗搓搓拉下代码一看,MD,这不是就是搭了个积木取名要你命3000吗?你还不能说人家说自己写了一个框架不对,何况这个框架通常也很好用。
用pytest就不更用说了,连并发都有两个库,一个xdist,一个pytest-parallel,每次都患选择恐惧症。
再有,开源的框架,毕竟普适多于贴合,跟自己的业务有时候就不那么紧密,为了使用某个具体功能还得引入很大一个包,也不是非常方便,另外最关键的一点是,我总觉得自己还行,想站起来试试 :)
框架是什么?我是怎么考虑框架的?
之前分享过几篇文章,
测试框架之我见
web自动化框架实践指南
Python接口测试框架实践
pytest框架从入门到精通
《测试框架之我见》, 《web自动化框架实践指南》, 《接口测试框架实践》, 《pytest框架从入门到精通》。 这些都是我工作的一些感悟,和对框架的一些思考,可以看到思想也是循序渐进的。你也可以看到不是“官方”框架,就是二次开发的“官方”框架。 当然也可以说我是常怀觊觎之心,不停研究的目的就是我个人非常想有一套完全自己实现的框架。
什么是ktest?
一句话:
ktest is a common test framework support for Both UI and API test with run in parallel ability。
跟其它的框架有什么不同?
除标准库之外,原则上不引入任何第3方库,所有的一切都自己实现。比如并发就老老实实自己设计规则多线程并发,不用xdist或者pytst-parallel了,比如错误重跑,HTML报告都是自己实现了。
参考了谁?
我当然不是闭门造车,参考了unittest,pytest,ddt,还有自己公司的官方框架, 读了部分源码,研究了下部分功能实现原理。
实现的功能:
1.多线程并发。(整套框架代码没出现任何哪怕一句threading,实现了并发,神奇不,嘿嘿)
2.分布式并发。(借助selenium-grid)
3.数据驱动。(一条用例两条数据会被当成两个用例,并展示在最终报告里)
4.同个测试类数据共享,每个测试用例数据独立。setUpClass, tearDownClass, setUp, tearDown(一看就是unittest的概念,只不过我自己实现了)。
4.动态生成,挑选,运行测试用例。(大量借助装饰器)
5.Web UI自动化测试每条用例错误自动截屏,记录log信息,自动重跑机制。
6.HTML报告。
7.XML格式for Jenkins。(马上完成,姑且算完成吧)
现在还是第一版,我个人想把它写成一个通用的测试框架,即可服务于web UI自动化测试,又可服务于API测试。当然还有很长的路要走。
详细介绍
先不介绍技术细节, 先把自己放在一个业务测试,或者刚接触自动化脚本的测试角色上,我拿到了一个测试框架,我最先想到的是什么? 如何用对吧? 用这个框架,我原有的测试用例需要做哪些改变?这个框架有哪些方便?你对框架的期待有哪些?
1.使用简单,介绍详细。
2.能让我方便的查找, 生成, 运行, 清理测试用例及测试数据。
3.对业务的侵袭小,我迁移成本低。
4.功能强大,报告美观。
5.稳定,bug少。
下面就详细介绍:
安装:
|
|
你的项目应该包括哪些:
在讲用法前,我们先来直观看下,你的项目目应该是什么样子的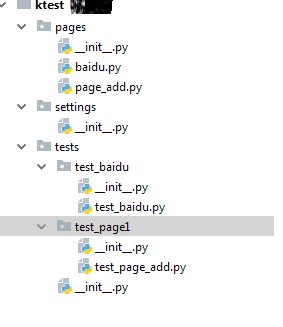
你的项目中应该包含:
1.pages package, 这里面放你所有待测试页面,每个页面作为一个page object来保存。
2.tests package, 这个文件夹下面放所有的测试用例,包括你的数据驱动,断言都在这里。
3.settings package, 这个里面放了一些框架里会用到的参数,当然也可以放你自己的配置。 如果你不知道框架用到哪些变量,你可以暂时不建立它,运行时框架会帮你自动生成。
可以看到,你只需要把精力放在你本身的业务上就好了。
ktest框架组成
package建立好了,我的测试用例,及我的待测页面要如何组织才能接入框架呢? 别急,我们先来看看框架本身长什么样子。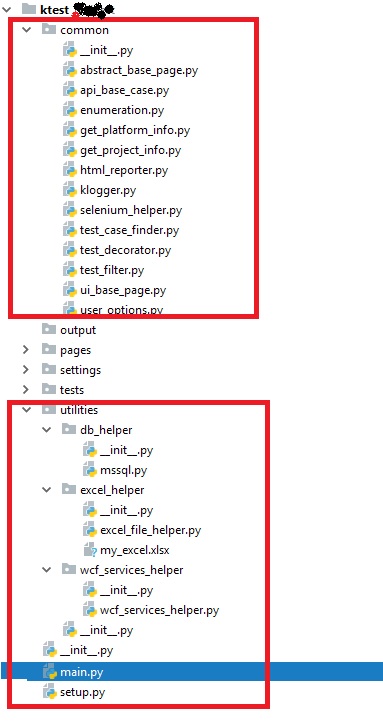
功能列表
看用红框标记起来的部分:
Common – 框架精华
1.欢迎关注公众号iTesting,跟万人测试团一起成长。
2.abstract_base_page.py 这个文件有是为了你自己项目的pages准备的,你的每一个待测页面或者功能都应该继承自这个文件中的类,并重写一些特定的函数。
3.api_base_case.py 创建了为api测试而用的基类。
4.enumeration.py 一些枚举变量,比如测试类的setup 和tearDown等,主要为了防止代码里写错及方便修改。
5.get_platform_info.py 判断运行的系统环境是windows,还是linux, 框架开始前会清理执行环境。
6.get_project_info.py 用于拿到你的项目文件的根目录。
7.html_reporter.py 用于生成HTML报告。
8.klogger.py 用于全局logger或者每个case独立logger。
9.selenium_helper.py 基于selenium封装的一些toolkit, 比如打开浏览器,使用chrome headless模式,关闭浏览器等。方便你快速开展工作。
10.test_case_finder.py 用于测试用例的查找和组织。 根据你的用户输入来进行,默认从tests 这个package下找所有被标记为@TestClass, @Test并且enable的用例。
11.test_decorator.py 用于标记测试类,测试用例,并且赋予每个测试类和测试用例独特的属性,方便test_case_finder查找。
12.test_filter.py 所有测试用例查找到后,根据用户的输入进行filter,最终保留出当次运行需要的测试类,测试函数及测试数据的组合。
13.ui_base_page.py UI的公用页,所有的UI Case 都继承自此。
14.user_options.py 接受用户参数并分析,最终为框架所用,包括要哪些用例运行,这些用例比如属于哪个组,那个测试类, 多线程还是单线程。 都在这里设置。
utiilites – 拿来即用测试套件
这里面放一些半成品,比如连接数据库脚本,比如用excel做数据驱动,对excel进行读写的脚本。 用户不需要操心连接的建立,销毁等。
main.py 用来运行框架,并发运行控制也是在这里。并发我“舍弃”了threading.Thread, 代码量下降一半以上,且不用操心锁。
setup.py 用来把框架打包。
集成你的项目
框架也看了,我的项目也建了, 我们的测试类和测试方法应该怎么写?
还拿我一直用的baidu来举例,你的项目pages package下
每一个你的测试类(待测页面)你需要:
1.测试类继承AbstractBasePage, 然后page_object模式就可以使用了。
2.测试类要实现is_target_page函数,返回值是True或者False, 运行中如果返回值False,会Raise Error并停止本测试类后续运行。
3.如果你不用page objectmm模式,你无需遵守上述规定。
你的tests package下测试用例定义
注意事项
我来仔细解释下:
1.test_case_id: 是测试报告里要显示的test_case_id, 一般跟你testcenter里的test_id相同,如果你一个测试类共用一个id, 你定义为类属性就可以。 如果你每个测试用例不同id,你在每个测试函数里,重写它就可以。 框架会为你替换。
2.tags: 是每个用例的tag,定义在类属性里,test_finder查找时会解析这个tags,可以是str或者list或者tuple,或者是3者的嵌套。 框架最终会解析成一个list。
比如你定义 tags=[‘smoke’,’bvt’] 和你定义 ‘smoke, bvt’是一样的效果。 当用户指定了要跑的tag属性时候,test_finder会根据它的值来做filter。
3.@SetUpClass(), @TearDownClass() 测试类装饰器,无输入参数。 每个测试类,不管它有多少个测试用例,这两个装饰器装饰的函数只会被执行一次。 一般用作测试类公用的数据的初始化,比如说,连接db查找某些值。 请注意, 并发运行,不要在这个函数里初始化你的browser,会有共享问题。
4.@TestClass(), 测试类的装饰类, 函数接受两个个参数一个是group,就是测试类所属的group,一个是enabled,默认值True。 值为False时, test_finder会把这个测试类略过。
5.@Test(), 测试装饰类, 函数接受一个参数enabled,默认值True。 值为False时, test_finder会把这个测试函数略过。
6.@data_provider(), 数据驱动装饰器。 接受一个参数,且此参数必须要iterable. 因为是数据驱动,不太可能只有一个数据,所以这个iterable,我通常我会定义成一个tuple,如果 有多个就是多个tuple, 例如[(1,2,3),(4,5,6)]这种,(1,2,3)会被解析成一条测试数据, (4,5,6)会被解析成另外一条。 这个概念来自ddt,我之前也介绍过相关框架。
7.@setUP(), @tearDown().两个函数,每个测试类必须定义,否则运行时框架会报错。 用作每个测试类的测试函数即每一条测试用例的运行前初始化和运行后的清理。
定义一次, 由它装饰的函数会在每个测试用例运行前后调用。 一般在里面初始化web browser和 API的 session。
测试函数,就是以@Test()装饰的函数,一般是你的业务代码,你需要自己实现业务流程的操作和断言。如果用到setUpClass或者setUp里的方法属性,你只需要在这些属性前加self.
它不像pytest或者unittest,此函数名不必以test开头或结尾。
以上基本参照了pytest和unittest的用法,主要初衷也是为了减少迁移成本。
好,我测试类,测试函数都写好了,如何跑呢?
可用参数
|
|
其中:
-t 是你要运行的测试目标的根目录,默认是项目下的tests文件夹。
-i 是测试类里定义的tags。 tags会被解析成list,用户指定的任何tag只要包含在这个lists里,并且这个测试函数所属的TestClass()是enabled和这个测试函数的enabled是True,就表示这个测试类的这个测试函数会被test_filder找到。
-I 是装饰测试类的@TestClass()定义的group,包含两个参数, 符合用户指定的group并enabled, 那么它装饰的类会被当作一个测试类被test_finder找到。
-e 是测试类里定义的tags。 tags会被解析成list。 用户指定的任何tags包含在list里,这个测试函数就会被test_finder忽略。
-E 是测试类里定义的tags。 tags会被解析成list。 用户指定的任何tags包含在list里,这个测试函数就会被test_finder忽略。
-n 并发执行的个数,默认是cpu_count。
-r 错误重跑, 默认是True。重跑再错误,所有跟case相关的log和screenshot会被记录。
Note:
1.这种默认下,测试用例(测试类)的tags解析出来的的任意子集,如果用户指定的group或者tag是包含它,那么他会被test_finder找到。 比如-test就跑包括了test这个tag的用例。 比如你有两个测试类,一个测试类的tag是test,另外一个测试类的tags是regression, 用户给了-i test,regression. 那么这两个测试类所属的测试用例都会被扫描到并且添加进待测list里。
2.所有的用户输入只支持str。 tag本身不必要加引号,除非它在测试类里也加了引号。 且多个tag直接用逗号隔开即可,不必加空格。
有的同学会问了,我希望跑同时包括test和regression在内这两个tags的用例呢? 谁提出的这个需求?我真想指着你的鼻子说:
没有问题,统统实现!
测试报告
下面我们看下一个运行实例
执行中console的输出: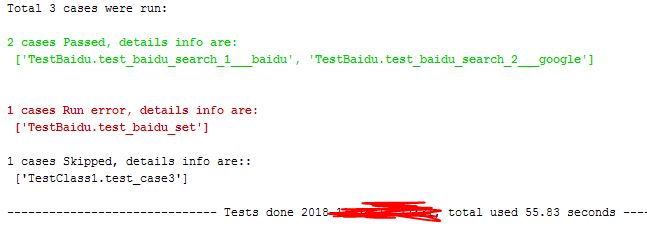
执行成功后报告的展示:
report会自动生成在你项目根目录下,以运行时时间戳为文件夹,每个测试用例一个子文件夹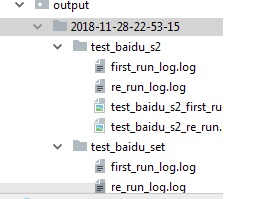
测试报告加入了run pass, run fail, run error的图表。 run fail代表真正的fail, run error代表代码有问题或者环境问题导致的错误。
同样报告直接按照测试类filter。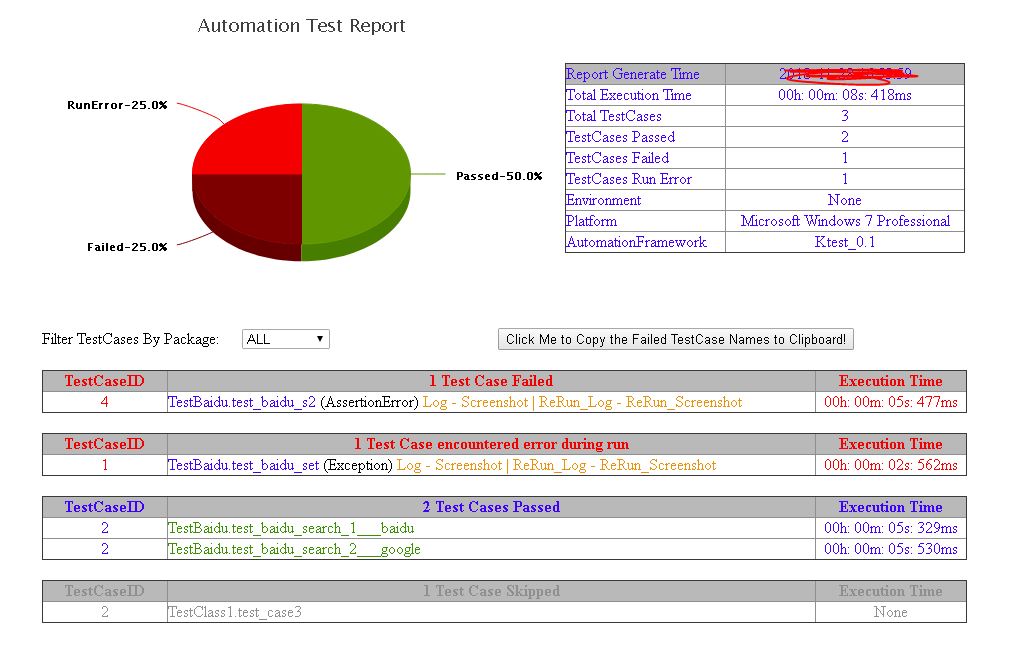
后记:
到此为止,ktest基本成型,也能根据需求完成web UI自动化和API自动化的工作了,不同无非是你在setUP初始化你的driver时候初始化的是你的browser还是request.session. 如果你想实现分布式并发,也可以在setUP initial selenium Grid, 前提是配置好selenium-server。
还是有一些感悟:
1.框架真不是一蹴而就的,是逐渐演化的。 最后成型的这一版跟我初始的规划还是有很大差距,有些代码甚至是不得已的妥协,比如我要出html报告,就要很多测试函数无关的数据收集,那么这些数据势必会侵入我的代码,结果就是我返回的测试函数数据结构很不简洁。
2.我最得意的是没有用大家都推崇的多线程threading.Thread,整个框架没有一行threading.Threadd 代码而实现了多线程并发,可阅读性增加了,而且我的代码量也因此少了三分之一, 虽然踩了不少坑,但也证明条条大路通罗马,只要理论通了,怎么实现,完全看个人喜欢。实际上threading.Thread实现太过繁琐,我几乎是一开始就否定了它。
3.你完全不需要搭积木, 一砖一瓦也能创建出漂亮的房子。
彩蛋:
放部分代码段: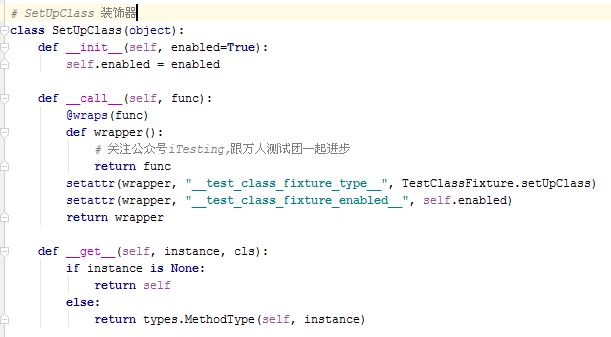
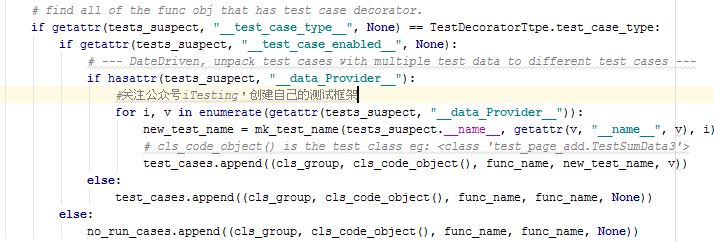
关于更多技术实现细节,我会重新写一篇文章介绍。


